Multi-layer email protection
Rspamd combines reputation, sender authentication, content analysis, and machine learning to stop phishing, fraud, malware, and spam — with the performance and flexibility to run anywhere from a single mailbox to the largest multi-tenant platforms.
High-Speed Processing
Written in C with a fully asynchronous, event-driven core, Rspamd scans hundreds of messages per second per core in real time — scaling from a single server to billions of messages a day.
Content Filtering
Match on every part of a message with regular-expression rules, maps, and selectors — headers, MIME structure, URLs, and body text — for precise, fully customizable detection logic.
Policy & Reputation Filtering
Reject bad senders early with DNS blocklists (RBL/URIBL), IP and URL reputation, greylisting, and rate limiting — before expensive content scanning ever runs.
Sender Authentication
Validate SPF, DKIM, DMARC, and ARC to confirm a message really comes from where it claims — stopping exact-domain spoofing and the forged senders behind phishing and BEC.
Malware & Malicious Attachments
Integrate ClamAV and commercial antivirus engines to catch malware and dangerous attachment types before they reach users' inboxes.
Adaptive Statistical & Neural Detection
A multiclass Bayes classifier and a neural network learn from your own traffic to catch evolving spam, scams, and phishing — with per-class policies that fit multi-tenant environments.
AI & LLM Content Analysis
Detect novel phishing and fraud by meaning, not keywords. The GPT plugin (OpenAI or local Ollama) and LLM embeddings in the neural module flag scams and social engineering that signature rules miss.
Easy SpamAssassin Migration
Already running SpamAssassin? Rspamd loads SA-format rules and scores directly, so you can migrate gradually and keep years of tuning instead of starting over.
Works With Your Mail Stack
Deploys in front of Postfix, Exim, Sendmail, and other MTAs, with native support in many mail platforms. Add protection without ripping out your infrastructure.
Threat Visibility & Analytics
See which campaigns hit you and what got blocked. ClickHouse and Elasticsearch integration give deep insight into attack patterns, detection rates, and blind spots.
Real-Time Monitoring
Watch verdicts as they happen and inspect exactly why any message was blocked through the built-in web interface.
Extensible & Programmable
A modular design with Lua scripting lets you write custom rules and respond to new threats and outbreaks in minutes, not release cycles.
Rspamd Console
Know which phishing, BEC, and spam campaigns reached your users, what the engine blocked, and where your blind spots are. Detection-impact analysis, symbol introspection, live mail-stream capture, and LLM-assisted rule authoring — drop-in next to your existing Rspamd cluster.
Explore Rspamd Console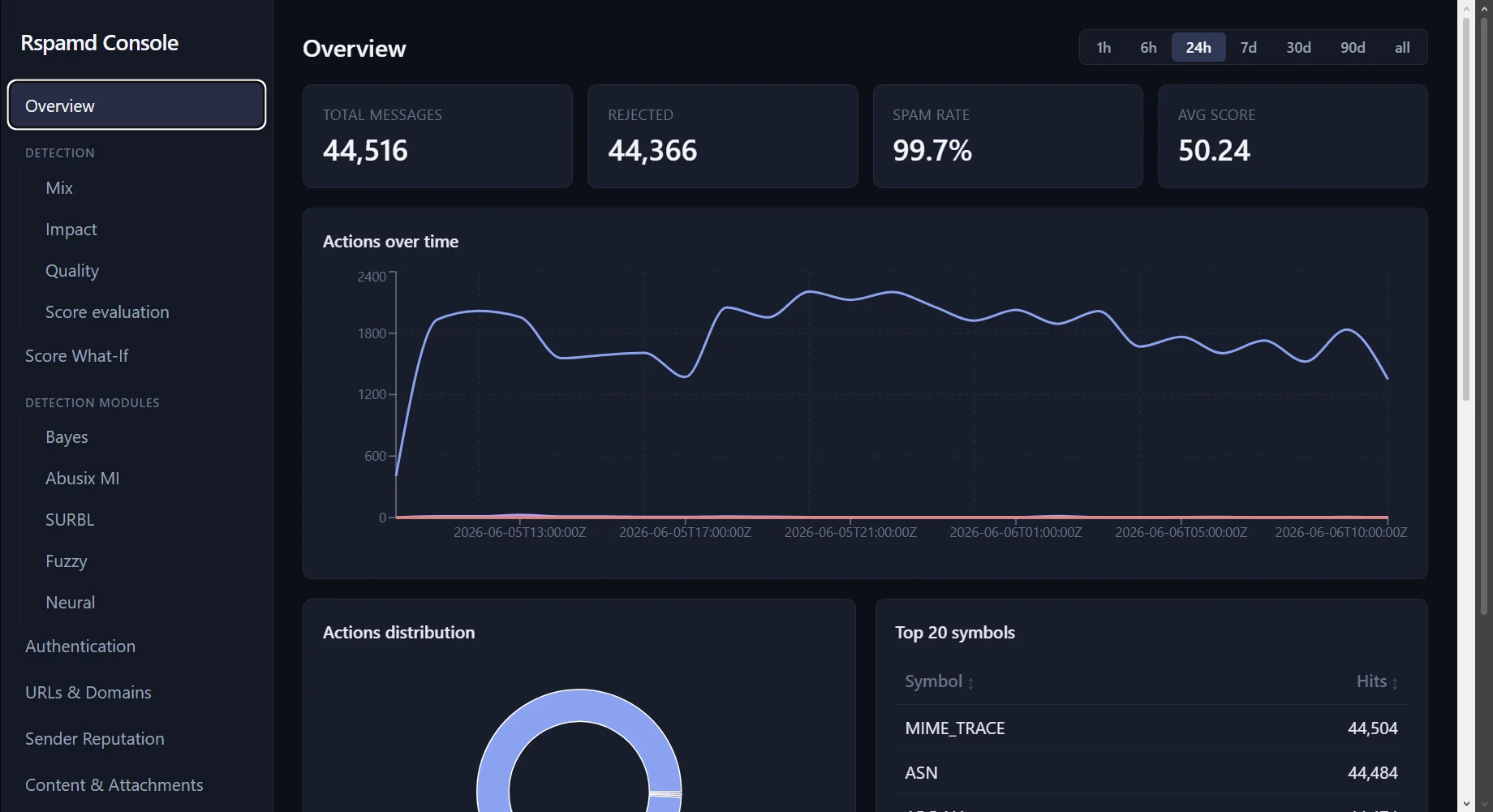
Open Source You Can Verify
Rspamd's detection engine is open source under the Apache 2.0 license — so you can audit exactly how messages are scored, run it entirely on your own infrastructure, and never be locked into a black box. Eighteen years in production and 100k+ installations stand behind it.
Auditable Detection Logic
Every rule, score, and model is open under Apache 2.0. Security teams can review exactly why a message was blocked — no opaque, black-box verdicts.
Your Data, Your Infrastructure
Run the full engine on-premises with Redis and ClickHouse. Message content stays in your environment, with no mandatory dependency on a vendor cloud.
No Vendor Lock-In
Works with your existing MTA and tooling through documented module and Lua APIs. Extend, replace, or migrate any component on your own terms.
Antivirus & Ecosystem Support
Plug in ClamAV and commercial antivirus engines, and draw on the broad integration ecosystem built up over years of open development.
Maturity You Can Trust
In production since 2008 across 100k+ installations, and continuously updated with the latest detection techniques and security fixes.
Premium Protection & Support
Premium plans add stronger detection data, priority support with response-time SLAs, and direct access to the engineers who build Rspamd — so your email security is backed by accountability, not just a community forum.
Scale
Scalable solution for businesses and larger organizations
- Fuzzy premium database & bulk service
- 5K mailboxes included
- Scalable to your demands
- Backed by the Rspamd core team
Enterprise
Complete solution with full support
- Rspamd Console
- Neural/FastText models
- Priority support & SLA
- Custom development & training
Hosted
Fully managed Rspamd deployment for organizations with dedicated budgets
- Everything in Enterprise
- Fully managed deployment
- Runs on your or our infrastructure
Trusted by email and security teams
See why IT security leaders choose Rspamd Premium for their critical email infrastructure.
"Rspamd's performance can only be compared with some extremely expensive brands available on the market. Beyond that, it has a wealth of powerful features and algorithms that make it an amazing tool against spam and other email abuse. Rspamd is broadly customizable and allows multiple strategies to avoid spam and false positives. In conclusion, the Rspamd team not only gives incredible support to Locaweb but has also been a great partner."
Rafael Abdo
Computer Security Incident Coordinator, Locaweb
Ready to protect your email?
From a single mail server to multi-tenant platforms handling millions of messages a day, Rspamd gives security teams the detection, control, and visibility to stop email threats. Talk to us about premium protection and support — or deploy the open-source engine today.